
前前后后用了好久才将系统搭建过程完成,当中遇到不少问题,郁闷了好长时间,感谢大黄同学的帮助,下次他发博客打赏喽。
我将以借鉴的博客的博文顺序补充细节,告诉作为新手的我们可能会遇到的问题。linux的基本操作指令一定要熟悉,比如文件解压命令(tar -zxvf jdk-8u77-linux-x64.tar.gz到当前文件夹下),文件的移动(mv),还有基本的vim命令。
这个链接就是借鉴的博客地址:
这是大黄同学总结的linux指令,很实用:
这个里面有vim的指令脑图,做的相当好偶(被强迫推荐,手动捂脸)
- Docker安装及配置
- 使用tag命令来为一个镜像打标签:docker tag <mirror id> <tag>
这个语句缺少一个部分,需要给你的镜像添加镜像的来源repository,例如ubuntu:spark。
这里的spark是tag.还有这里有一个技术路线图,是整个操作的示意图,十分清晰明了,一定要看懂后在动手。
- ssh安装及配置
- 我的前一篇博文清楚的介绍了什么是ssh所以本处就不解释了。添加几个命令的注释:
docker --name cloud1 -h cloud1 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it ubuntu
这个命令严格来说应该在docker 后面加run命令参数。
apt-get install ssh
使用apt工具包下载前最好用:apt-get update更新一下,以免造成下载失败。我配置时有错误提示说配置的目录未找到,可能是版本不同里面的文件有变化,当出现找不到文件,可以自己用shell命令新建需要的文件即可。
- 基础环境安装
- 包括后面一堆需要的软件下载都不是apt-get工具可以搞定的。需要用wget.
wget是linux最常用的下载命令, 一般的使用方法是: wget + 空格 + 要下载文件的url路径
例如:wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
简单说一下-c参数, 这个也非常常见, 可以断点续传, 如果不小心终止了, 可以继续使用命令接着下载
例如: # wget -c http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
下面详细阐述wget的用法:
wget是一个从网络上自动下载文件的自由工具。它支持HTTP,HTTPS和FTP协议,可以使用HTTP代理.
所谓的自动下载是指,wget可以在用户退出系统的之后在后台执行。这意味这你可以登录系统,启动一个wget下载任务,然后退出系统,wget将在后台执行直到任务完成,相对于其它大部分浏览器在下载大量数据时需要用户一直的参与,这省去了极大的麻烦。
wget可以跟踪HTML页面上的链接依次下载来创建远程服务器的本地版本,完全重建原始站点的目录结构。这又常被称作”递归下载”。在递归下载的时候,wget遵循Robot Exclusion标准(/robots.txt). wget可以在下载的同时,将链接转换成指向本地文件,以方便离线浏览。
wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性.如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
-
我们搭建环境需要下载:
需要下载软件列表软件名称 版本 java 1.8.0_77 scala 2.10.6 Zookeeper 3.4.8 hadoop 2.6.4 spark 1.6.1 在linux中的压缩包大多以tar.gz或tgz两种。具体的下载地址去该软件的下载官网,然后挑选合适版本的下载文字,右键选择下载地址即可得到地址,使用wget命令下载。具体如下:
先打开java下载官方主页:l
然后我们可以选择合适版本并获取地址:
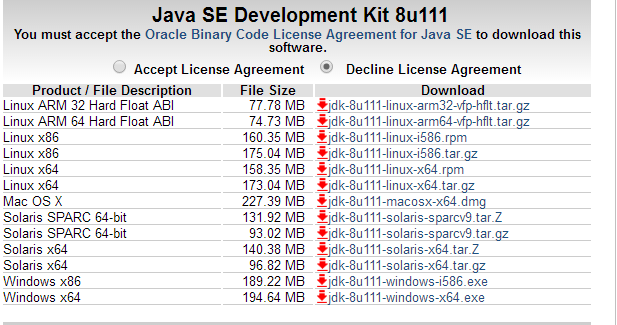
http://download.oracle.com/otn-pub/java/jdk/8u111-b14/jdk-8u111-linux-x64.tar.gz
- 集群部署
- 到这一步基本整个过程快要结束,
zkServer.sh start
在所有节点启动zkserver后,在所有节点查看Zkserver运行状态,
Zkserver.sh status
效果如下图: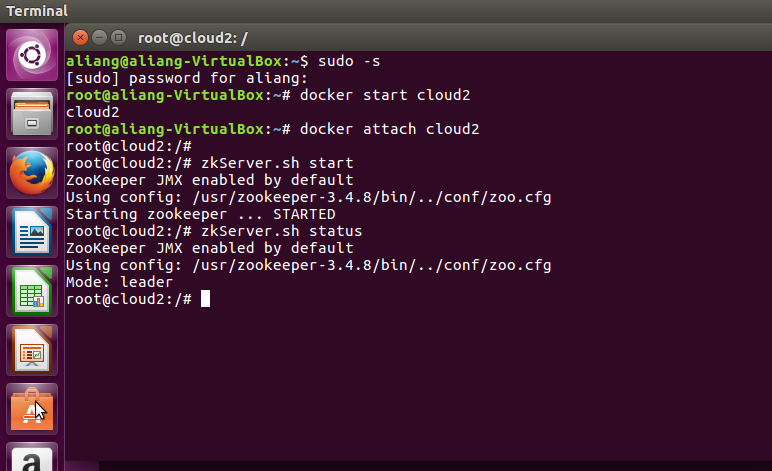
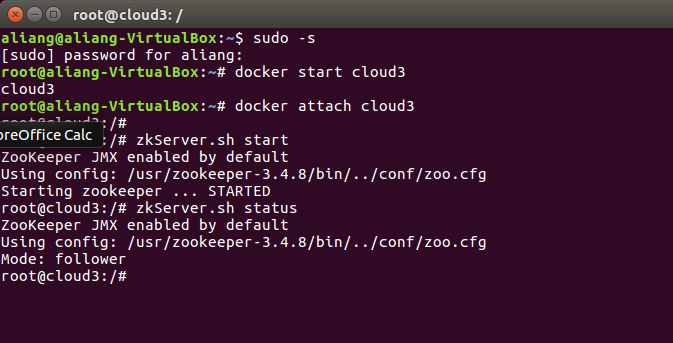
重点是:显示连接不到Zkserver的错误,如果等待10分钟还不行,重启虚拟机也可以一试。